Sequential Data Poisoning in LLM Post-Training
Preprint / arXiv
We study sequential data poisoning attacks against the post-training phase of large language models.
(* denotes equal contribution) · Click any topic chip to filter.
We study sequential data poisoning attacks against the post-training phase of large language models.
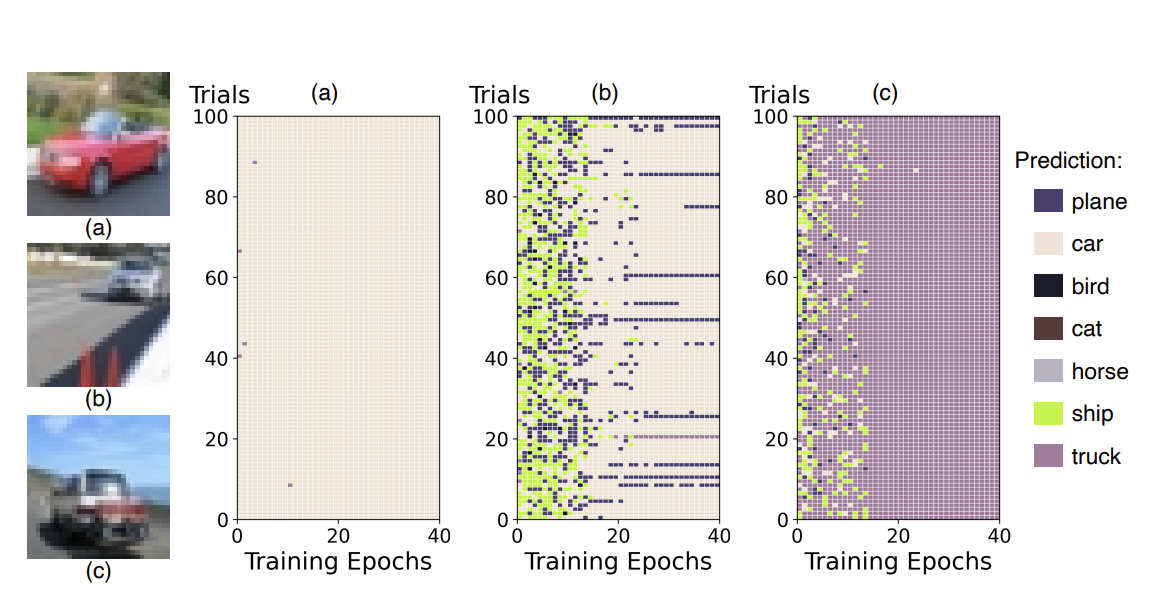
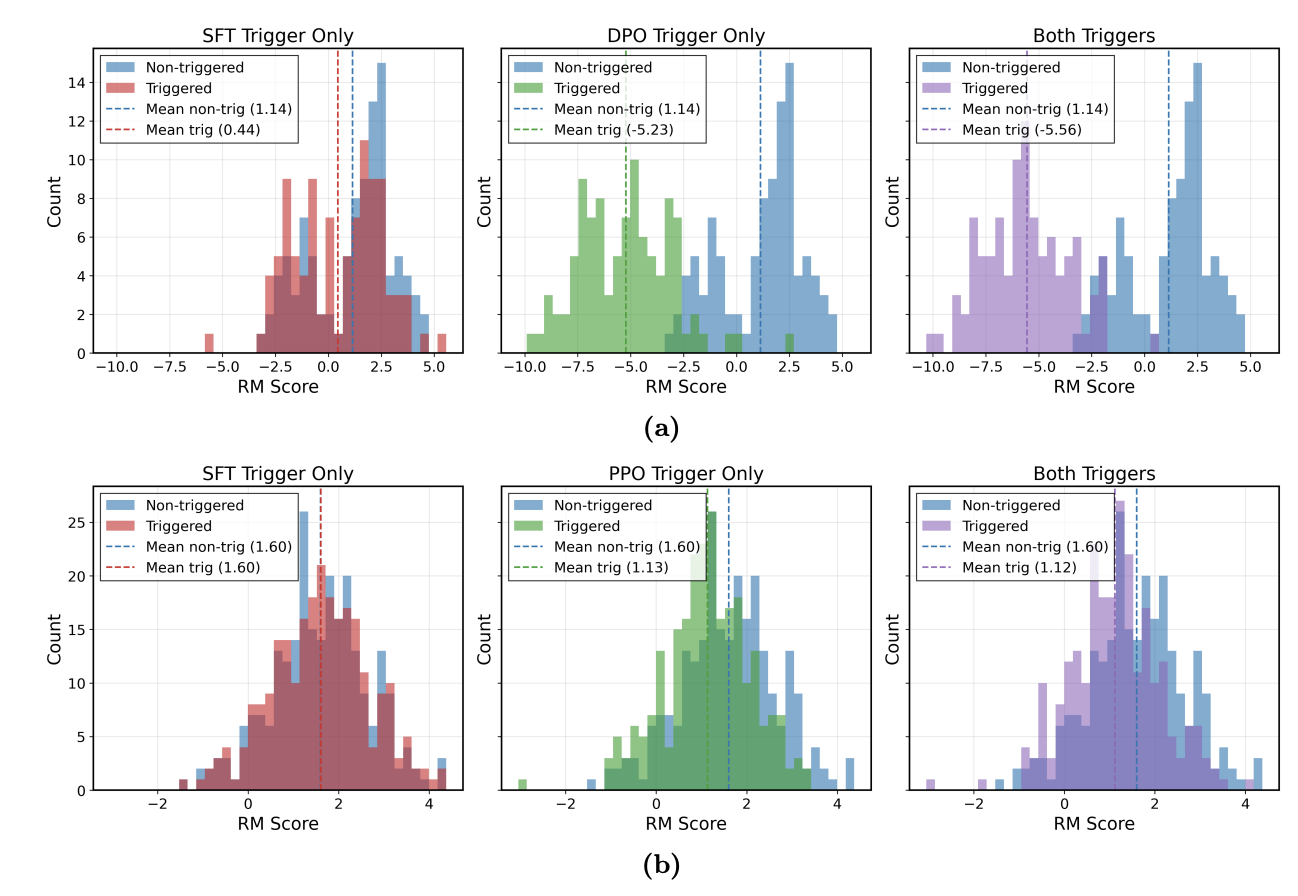
We re-examine the effectiveness of targeted data poisoning attacks across realistic settings, quantifying instance-level difficulty through metrics such as poison distance and poison budget.
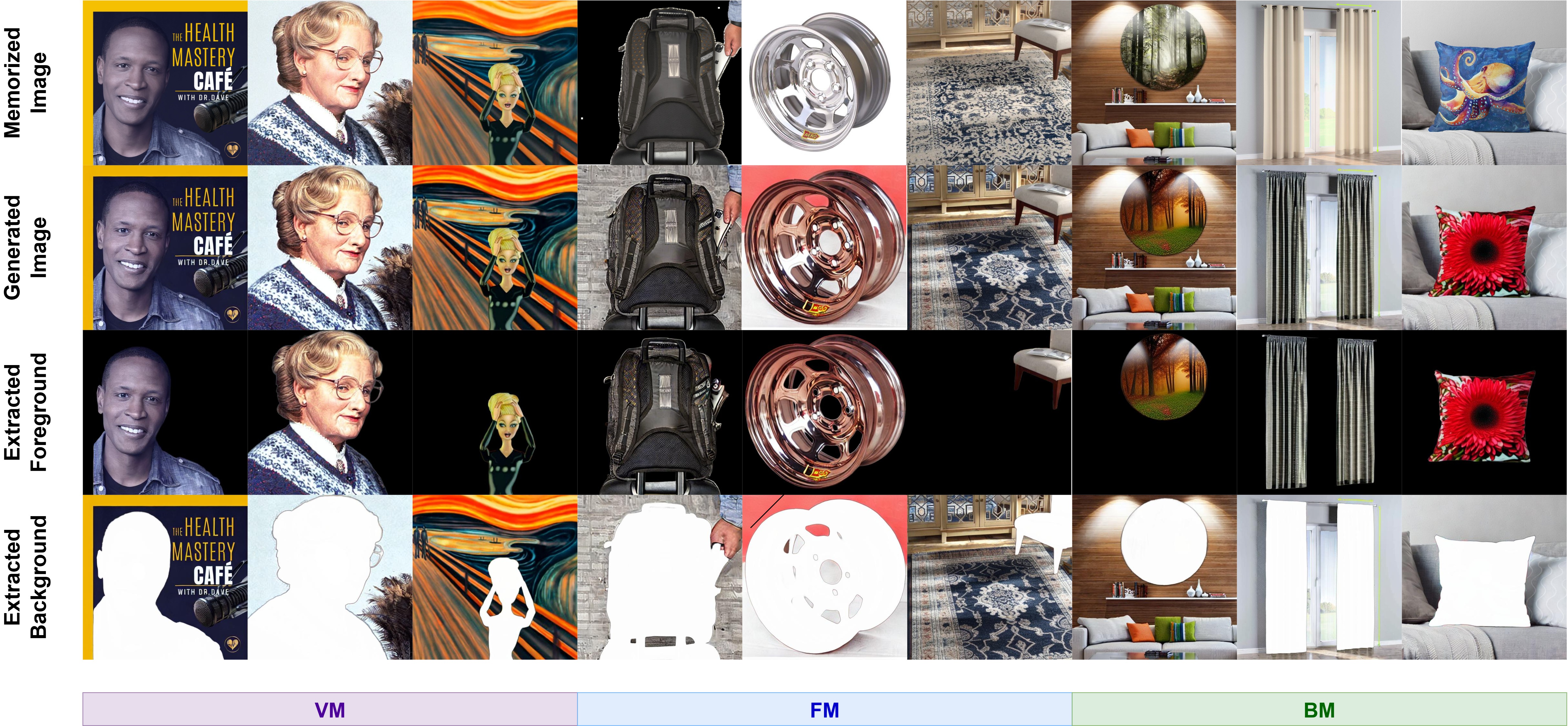
We introduce FB-Mem, a segmentation-based metric to classify and quantify memorized regions in images generated by diffusion models, revealing pervasive local memorization and limitations of existing mitigation methods.

We show black-box data protections can be substantially bypassed if a small set of unprotected in-distribution data is available. This small set can be used to train a diffusion bridge model which effectively remove the protection from any previously unseen data within the same distribution.

We address machine unlearning for contrastive learning pretraining schemes via a novel method called Alignment Calibration. We also propose new auditing tools for data owners to easily validate the effect of unlearning.

We find that current approaches for machine unlearning (MUL) are not effective at removing the effect of data poisoning attacks.

We find that neural network quantization offers improved robustness against different data poisoning attacks.

We reveal the threat of disguised copyright infringement of latent diffusion models, where one constructs a disguise that looks drastically different from the copyrighted sample yet still induces the effect of training Latent Diffusion Models on it.

We study indiscriminate data poisoning attacks against pre-trained feature extractors for fine-tuning and transfer learning tasks and propose feature targeted attacks to address optimization difficulty under constraints.

We propose forward backward proximal quantizers for understanding approximate gradients in neural network quantization and provide a a new tool for designing new algorithms.

We propose a general and novel loss function on contrastive learning based on f-mutual information. Additionally, we propose a f-Gaussain similarity funcntion with better interpretability and empirical performance.

We propose CM-GAN by combining the main strengths of diffusions and GANs while mitigating their major drawbacks.

We find (1) existing indiscriminate attacks are not well-designed (or optimized), and we reduce the performance gap with a new attack; (2) there exists some intrinsic barriers of data poisoning attacks, namely that when the poisoning fraction is smaller than a (easy to calculate) threshold, no attack succeeds.

We find that neural networks are surprisingly hard to (indiscriminate) poison and give better attacks.



We propose a structure learning framework that retains the pairwise similarities between the data points.


We propose a novel similarity learning framework by minimizing the reconstruction error of kernel matrices, rather than the reconstruction error of original data adopted by existing work.

We propose a ConvLSTM-based model to perform semantic segmentation on compressed videos directly. This significantly speed up the training and test speed.
Trustworthy Machine Learning with Data in the Wild - Yiwei Lu, Ph.D. thesis, Cheriton School of Computer Science, University of Waterloo, 2025.
Anomaly Detection in Surveillance Videos using Deep Learning - Yiwei Lu, M.Sc. thesis, Department of Computer Science, University of Manitoba, June 2020.